Data can take various forms and be classified based on different criteria, which are important for understanding and managing data effectively. In this article, we will explore the concepts of structured, semi-structured, and unstructured data, the differences between them, and their use cases. We will also discuss the importance of data classification and provide examples of each data type.
What Is Data?
Data refers to a collection of information stored in a digital format, encompassing various facts, observations, and numerical values that are used in decision-making processes. Data can come in different forms, including structured, semi-structured, and unstructured, and it serves as the foundation for analysis, insights, and informed decision-making in various fields and applications.
Introduction to Data Classification
Data Classification Types:
Data can be categorized into various types based on different criteria, which help us understand and work with data effectively. Some common data classification types include:
- Quantitative vs. Qualitative Data: In an academic context, data is often classified as quantitative (numeric) or qualitative (non-numeric). For example, economic indicators are quantitative data, while interview responses are qualitative data.
- Entity or Business Process Data: Data can be categorized based on the entity or business process it relates to. In a business setting, common categories include customer data, employee data, and sales data.
- Master vs. Transactional Data: Master data is relatively static and shared across an organization, such as customer information. Transactional data, on the other hand, describes events and is more dynamic, such as product orders and website logs.
- Structured, Semi-Structured, and Unstructured Data: Data can be classified based on its degree of organization. Structured data is highly organized, semi-structured data has some organization, and unstructured data has no predefined format.
Structured Data
Structured data is highly organized and typically stored in formats like spreadsheets or relational databases. This organization allows for easy analysis and machine readability. Structured data is valuable for data visualization, analytics, and machine learning.
Structured Data Examples:
- Customer data in a spreadsheet.
- Product information in a relational database.
- Structured data can also be stored in CSV (comma-separated values) files.
Semi-Structured Data
Semi-structured data falls between structured and unstructured data in terms of organization. It contains some level of structure, often introduced through tags or elements, but the degree of organization can vary. HTML and JSON files are examples of semi-structured data.
Semi-Structured Data Examples:
- HTML files, where content is organized with tags like
<h1>or<p>. - JSON files with a tree-like structure, allowing for some organization.
Unstructured Data
Unstructured data lacks a predefined organizational form or specific format. It represents the majority of data generated today, including text, chat, video, and audio content. While easy for humans to consume, unstructured data is challenging for computers to interpret. Advances in AI and machine learning are improving the processing of unstructured data.
Unstructured Data Examples:
- Images (e.g., JPEG).
- Videos (e.g., MP4).
- Songs (e.g., MP3).
- Documents (e.g., PDFs, DOCX).
Key Distinctions and Importance
Structured vs. Semi-Structured vs. Unstructured Data:
- Structured data is highly organized and machine-readable.
- Semi-structured data has some organization but is less rigid than structured data.
- Unstructured data lacks organization and is challenging for computers to analyze.
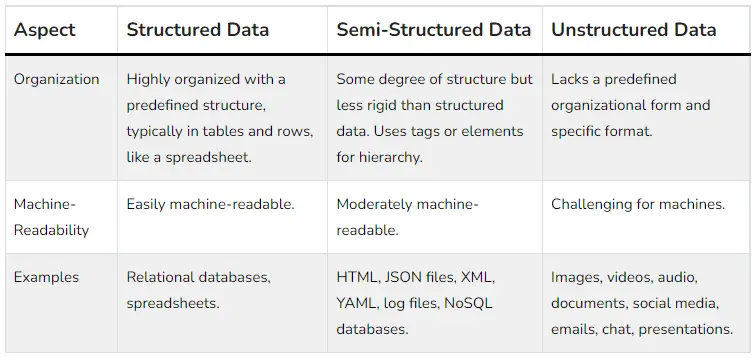
Here is a table comparing Structured Data, Semi-Structured Data, and Unstructured Data:
| Aspect | Structured Data | Semi-Structured Data | Unstructured Data |
|---|---|---|---|
| Organization | Highly organized with a predefined structure, typically in tables and rows, like a spreadsheet. | Some degree of structure but less rigid than structured data. Uses tags or elements for hierarchy. | Lacks a predefined organizational form and specific format. |
| Machine-Readability | Easily machine-readable. | Moderately machine-readable. | Challenging for machines. |
| Examples | Relational databases, spreadsheets. | HTML, JSON files, XML, YAML, log files, NoSQL databases. | Images, videos, audio, documents, social media, emails, chat, presentations. |
Importance of Data Classification:
- Machine-Readability: The degree of organization affects a data’s machine-readability. Structured data is highly machine-readable, enabling efficient analysis.
- Implications for Data Storage: How data is organized also impacts data storage methods. Structured data can be easily stored and analyzed, while unstructured data requires more advanced techniques.
In summary, understanding the classification of data into structured, semi-structured, and unstructured forms is crucial for effective data management and analysis. While structured data is highly organized and machine-readable, semi-structured and unstructured data present unique challenges and opportunities in the world of data analytics.