Mistral 7B, is a Large Language Model (LLM) of Mistral.AI, is a powerful AI algorithm that trained on large datasets to generate coherent text and perform various natural language processing tasks. Pre-trained LLMs are limited to next-token prediction, and as a result, they cannot perform specific tasks. The base models are then adjusted to serve as helpful assistants by fine-tuning their instructions and answers.
In this tutorial, you’ll learn how to use and fine-tune the Mistral 7B model for natural language processing projects. You will be taught to load the model, run inference, quantize, fine-tune it, merge it and push it to the Hugging Face Hub.
Understanding Mistral 7B
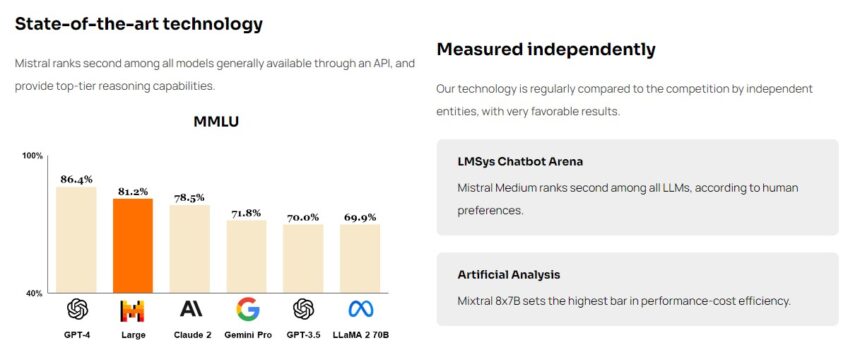
With great excitement, the Mistral AI team introduces the mistral 7B model as a new addition to the generative AI era. It’s a language model giant with 7.24 billion parameters and many new features.

The Mistral 7B is one of the most impressive, second major tongue models. Despite facing stiff competition from the Llama-1 34B, it outperforms the Llama-2 13B in all benchmark tests. Additionally, the Mistral 7B is adept at code-related tasks but still manages to perform well in English-language tasks. His versatility and strength are exemplified by this outstanding performance.
Both the code and the text model are released under the Apache 2.0 license, allowing it to be used without restriction. The Mistral 7B research paper (https://arxiv.org/pdf/2310.06825.pdf) outlines the model architecture, performance, and instruction refinement in greater depth.
Model Architecture
Mistral-7B-v0.1 is a transformer model, with the following architecture choices:
- Grouped-Query Attention
- Sliding-Window Attention
- Byte-fallback BPE tokenizer
Why Fine-tune LLMs
Fine-tuning is the best way to train a model about task-specific things. The process of training a pre-trained model involves using custom datasets to improve its performance on specific tasks. The refinement of the base model involves transfer learning, which updates its parameters to reflect the acquired knowledge.
Full fine-tuning involves updating all model parameters, but this can be expensive and unattainable for a larger developer team. This is where LoRA and QLoRA come into the picture.
Before we start, we have to install (if already install then need to update) the essential libraries to avoid any error.
! pip install transformers trl accelerate torch bitsandbytes peft datasets -qUFine-Tune Mistral-7B using LoRa
The most common way to access Mistral 7B is through Hugging Face. There is also a feature, called Models, provides a more convenient way to access the model. The model or dataset can be load or fine-tuned without downloading, and it takes only a few minutes to start the task.
Loading Dataset
First, we need to load our mosaicml/instruct-v3 dataset. It’s a great collection of effective and safe tasks.
from datasets import load_dataset
instruct_tune_dataset = load_dataset("mosaicml/instruct-v3")Dataset Formatting
Let’s take a peek at our dataset.
It’s our job to merge these prompt and response columns into a single formatted prompt for fine-tuning.
instruct_tune_datasetDatasetDict({
train: Dataset({
features: ['prompt', 'response', 'source'],
num_rows: 56167
})
test: Dataset({
features: ['prompt', 'response', 'source'],
num_rows: 6807
})
})Since we want to generate a model that generates instructions – we’re going to filter away all the subset datasets and only used the dolly_hhrlhf component!
instruct_tune_dataset = instruct_tune_dataset.filter(lambda x: x["source"] == "dolly_hhrlhf")
instruct_tune_datasetDatasetDict({
train: Dataset({
features: ['prompt', 'response', 'source'],
num_rows: 34333
})
test: Dataset({
features: ['prompt', 'response', 'source'],
num_rows: 4771
})
})We’re going to train on a small subset of the data – if you were considering an Epoch based approach this would reduce the amount of time spent training!
instruct_tune_dataset["train"] = instruct_tune_dataset["train"].select(range(5_000))
instruct_tune_dataset["test"] = instruct_tune_dataset["test"].select(range(200))
instruct_tune_datasetDatasetDict({
train: Dataset({
features: ['prompt', 'response', 'source'],
num_rows: 5000
})
test: Dataset({
features: ['prompt', 'response', 'source'],
num_rows: 200
})
})In the following function we’ll be merging our prompt and response columns by creating the following template:
<s>### Instruction:
Use the provided input to create an instruction that could have been used to generate the response with an LLM.
### Input:
{input}
### Response:
{response}</s>Let’s do it in python.
def create_prompt(sample):
bos_token = "<s>"
original_system_message = "Below is an instruction that describes a task. Write a response that appropriately completes the request."
system_message = "Use the provided input to create an instruction that could have been used to generate the response with an LLM."
response = sample["prompt"].replace(original_system_message, "").replace("\n\n### Instruction\n", "").replace("\n### Response\n", "").strip()
input = sample["response"]
eos_token = "</s>"
full_prompt = ""
full_prompt += bos_token
full_prompt += "### Instruction:"
full_prompt += "\n" + system_message
full_prompt += "\n\n### Input:"
full_prompt += "\n" + input
full_prompt += "\n\n### Response:"
full_prompt += "\n" + response
full_prompt += eos_token
return full_promptcreate_prompt(instruct_tune_dataset["train"][0])Loading the Mistral 7B base model
Next, we will implement 4-bit quantization with NF4-type setup using BitsAndBytes to load our model in 4-BIT precision. By reducing memory footprint and loading the model faster, it can be made compatible with Google Colab or consumer GPUs.
We’re going to load our model in 4bit, with double quantization, with bfloat16 as our compute dtype. You’ll notice we’re loading the instruct-tuned model – this is because it’s already adept at following tasks – we’re just teaching it a new one!
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
import torch
nf4_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=torch.bfloat16
)
model = AutoModelForCausalLM.from_pretrained(
"mistralai/Mistral-7B-Instruct-v0.1",
device_map='auto',
quantization_config=nf4_config,
use_cache=False
)
tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1")
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"
Let’s example how well the model does at this task currently:
def generate_response(prompt, model):
encoded_input = tokenizer(prompt, return_tensors="pt", add_special_tokens=True)
model_inputs = encoded_input.to('cuda')
generated_ids = model.generate(**model_inputs, max_new_tokens=1000, do_sample=True, pad_token_id=tokenizer.eos_token_id)
decoded_output = tokenizer.batch_decode(generated_ids)
return decoded_output[0].replace(prompt, "")generate_response("### Instruction:\nUse the provided input to create an instruction that could have been used to generate the response with an LLM.\n\n### Input:\nI think it depends a little on the individual, but there are a number of steps you’ll need to take. First, you’ll need to get a college education. This might include a four-year undergraduate degree and a four-year doctorate program. You’ll also need to complete a residency program. Once you have your education, you’ll need to be licensed. And finally, you’ll need to establish a practice.\n\n### Response:", model)<s>
To become a healthcare provider, you should pursue a college education, obtaining a four-year undergraduate degree and a four-year doctorate program. Afterward, you must complete a residency program. Once you have completed your education, you will need to become licensed. Finally, to establish a practice, you must have all of these steps completed.</s>Train the Model
Now, we’re going to prepare our model for 4bit LoRA training! We can use these handy helper functions to achieve this goal thanks to huggingface and the peft library!
The fine-tuning process employs PEFT LoRa, which is based on the Low-Rank Adaptation (LoRA) method. The term “matrix” is used to describe a significant amount of information that we use when teaching (training) our model. The technique known as LoRa enables the use of smaller matrices that represent larger ones. The mechanism functions by exploiting the abundance of repetitive materials in the vast matrix, particularly for our objectives.
Consider the entire list of tasks that can be learned, but only a portion of them is required for our specific task to be complete. LoRa assists us in concentrating solely on that minor aspect. This approach ensures that we don’t have to go back and read the entire list every time we train our model for our specific job. LoRa’s core principle is anchored by that!
The GPU space is decreased even more by this method, as the model doesn’t have to handle and store irrelevant data. LoRa’s main purpose is to optimize the utilization of GPU resources, resulting in faster training and reduced computing power consumption.
from peft import AutoPeftModelForCausalLM, LoraConfig, get_peft_model, prepare_model_for_kbit_training
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=64,
bias="none",
task_type="CAUSAL_LM"
)model = prepare_model_for_kbit_training(model)
model = get_peft_model(model, peft_config)All that’s left to do is set up a number of hyper parameters.
from transformers import TrainingArguments
args = TrainingArguments(
output_dir = "mistral_instruct_generation",
#num_train_epochs=5,
max_steps = 100, # comment out this line if you want to train in epochs
per_device_train_batch_size = 4,
warmup_steps = 0.03,
logging_steps=10,
save_strategy="epoch",
#evaluation_strategy="epoch",
evaluation_strategy="steps",
eval_steps=20, # comment out this line if you want to evaluate at the end of each epoch
learning_rate=2e-4,
bf16=True,
lr_scheduler_type='constant',
)Supervised fine-tuning (SFT) involves the use of labeled data to modify the pre-train Language Model (LLM) through supervised learning techniques. The weights of the model are adjusted based on the gradients obtained from the task-specific loss, which is measured as the difference between the predictions made by the LLM and the actual ground truth labels.
from trl import SFTTrainer
max_seq_length = 2048
trainer = SFTTrainer(
model=model,
peft_config=peft_config,
max_seq_length=max_seq_length,
tokenizer=tokenizer,
packing=True,
formatting_func=create_prompt,
args=args,
train_dataset=instruct_tune_dataset["train"],
eval_dataset=instruct_tune_dataset["test"]
)Next, we call the train function, here we train the model for 100 steps.
trainer.train()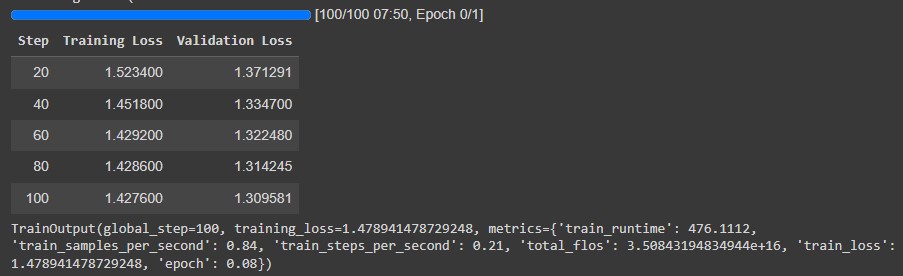
Save Model and Push to Hub
trainer.save_model("exnrt_mistral_instruct")!pip install huggingface-hub -qUfrom huggingface_hub import notebook_login
notebook_login()trainer.push_to_hub("exnrt/exnrt_mistral_instruct")Text the Trained Model
The fine-tuned model can be utilized for inference after the training.
def generate_response(prompt, model):
encoded_input = tokenizer(prompt, return_tensors="pt", add_special_tokens=True)
model_inputs = encoded_input.to('cuda')
generated_ids = model.generate(**model_inputs, max_new_tokens=1000, do_sample=True, pad_token_id=tokenizer.eos_token_id)
decoded_output = tokenizer.batch_decode(generated_ids)
return decoded_output[0]generate_response("### Instruction:\nUse the provided input to create an instruction that could have been used to generate the response with an LLM.### Input:\n--Your input text to test the model.\n\n### Response:", merged_model)🔻Fine-tuning mistralai/Mistral-7B-Instruct-v0.2
Fine-tuning mistralai/Mistral-7B-Instruct-v0.2
! pip install -U bitsandbytes peft accelerate trl datasets wandbImport
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig,HfArgumentParser,TrainingArguments,pipeline, logging
from peft import LoraConfig, PeftModel, prepare_model_for_kbit_training, get_peft_model
import os, torch, wandb
from datasets import load_dataset
from trl import SFTTrainerLogin to Hugging Face
from huggingface_hub import notebook_login
notebook_login()Login to wandb and Create Project
# Monitering the LLM
wandb.login(key = '')
run = wandb.init(
project='Fine-tuning-Mistral',
job_type="training",
anonymous="allow"
)Select Model and Dataset
base_model = "mistralai/Mistral-7B-Instruct-v0.2"
dataset_name = "mwitiderrick/lamini_mistral"
new_model = "Mistral-7b-v2-finetune"Manage Dataset
#Importing the dataset
dataset = load_dataset(dataset_name, split="train")
dataset["text"][100]Model and Tokenizer Loading
bnb_config = BitsAndBytesConfig(
load_in_4bit= True,
bnb_4bit_quant_type= "nf4",
bnb_4bit_compute_dtype= torch.bfloat16,
bnb_4bit_use_double_quant= False,
)
model = AutoModelForCausalLM.from_pretrained(
base_model,
quantization_config=bnb_config,
torch_dtype=torch.bfloat16,
device_map="auto",
trust_remote_code=True,
)
model.config.use_cache = False # silence the warnings. Please re-enable for inference!
model.config.pretraining_tp = 1
model.gradient_checkpointing_enable()
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(base_model, trust_remote_code=True)
tokenizer.padding_side = 'right'
tokenizer.pad_token = tokenizer.eos_token
tokenizer.add_eos_token = True
tokenizer.add_bos_token, tokenizer.add_eos_tokenAdding the adapters in the layers
model = prepare_model_for_kbit_training(model)
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=64,
bias="none",
task_type="CAUSAL_LM",
target_modules=["q_proj", "k_proj", "v_proj", "o_proj","gate_proj"]
)
model = get_peft_model(model, peft_config)Test Before Fine-tuning
prompt = "How to make banana bread?"
pipe = pipeline(task="text-generation", model=model, tokenizer=tokenizer, max_length=200)
result = pipe(f"<s>[INST] {prompt} [/INST]")
print(result[0]['generated_text'])print(model)Set Hyperparameter
training_arguments = TrainingArguments(
output_dir="./results",
num_train_epochs=1,
per_device_train_batch_size=4,
gradient_accumulation_steps=1,
optim="paged_adamw_32bit",
save_steps=25,
logging_steps=25,
learning_rate=2e-4,
weight_decay=0.001,
fp16=False,
bf16=False,
max_grad_norm=0.3,
max_steps=-1,
warmup_ratio=0.03,
group_by_length=True,
lr_scheduler_type="constant",
report_to="wandb"
)Setting SFT parameters and starting training
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
peft_config=peft_config,
max_seq_length= None,
dataset_text_field="text",
tokenizer=tokenizer,
args=training_arguments,
packing= False,
)
trainer.train()Save Model
# Save the fine-tuned model
trainer.model.save_pretrained(new_model)
wandb.finish()
model.config.use_cache = True
model.eval()Test Fine-tuned Model
prompt = "Can I find information about the code's approach to handling long-running tasks and background jobs?"
pipe = pipeline(task="text-generation", model=model, tokenizer=tokenizer, max_length=200)
result = pipe(f"<s>[INST] {prompt} [/INST]")
print(result[0]['generated_text'])Conclusion
The Mistral 7B LLM’s fine tuning is a captivating blend of theoretical concepts and practical implementation. The theoretical basis of this process enables you to comprehend the extent of customization achievable with such a robust language model. It’s important to remember that fine-tuning is often a laborious process that requires experimentation and refinement to achieve the best possible outcome. This theoretical guide provides you with the necessary knowledge to begin your personal creation of Mistral 7B, tailored to your individual preferences.