Jamba-v0.1 is one of the latest state-of-the-art Large Language Models available on Hugging Face. It’s a hybrid SSM-Transformer LLM that delivers throughput gains over traditional Transformer-based models while surpassing or matching the leading models of its size class on most common benchmarks.
This marks the first Mamba implementation at a production scale, opening up intriguing research and application possibilities. It’s a pretrained generative text model using a mixture-of-experts (MoE) with 12B active parameters (52B across all experts). It supports up to 256K context length, and with an 80GB GPU, it can hold up to 140K tokens per instance.
Since it did not go through any alignment for instruct/chat interactions, Jamba is a pretrained base model.
Why QLoRA?
QLoRA tackles the challenge of fine-tuning massive language models on a single GPU by combining two techniques: it reduces the number of parameters needed for fine-tuning and shrinks the model’s memory footprint by using lower precision for its weights, making it more efficient and resource-friendly.
Before fine-tuning, let’s understand how this model works 🤗.
How to Use Jamba-v0.1 Base Model
Jamba requires transformers version 4.39.0 or higher. To install:
pip install transformers>=4.39.0To run optimized Mamba implementations, you need to install mamba-ssm and causal-conv1d:
pip install mamba-ssm causal-conv1d>=1.2.0Now, import requirements components and load model:
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("ai21labs/Jamba-v0.1",
trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained("ai21labs/Jamba-v0.1")Add prompt and get output:
input_ids = tokenizer("In the recent Super Bowl LVIII,", return_tensors='pt').to(model.device)["input_ids"]
outputs = model.generate(input_ids, max_new_tokens=216)
print(tokenizer.batch_decode(outputs))Fine-tune Jamba-v0.1 on A100 – 40GB VRAM using QLoRA
A minimal example of Fine-tuning on a Colab (Pro) Notebook (A100 – 40GB).
A convenient tool to help you monitor and manage Nvidia GPUs on your system is the nvidia-smi command, which enables you to keep track of their performance (utilization, memory usage, temperature), manage multiple GPUs, and resolve problems in case of graphics-intensive applications.
! nvidia-smiInstall Flash Attention 2
! pip install ninja packaging flash-attn --no-build-isolationInstall Required Dependencies
! pip install -U "transformers>=4.39.0" mamba-ssm "causal-conv1d>=1.2.0" peft trl bitsandbytesNow, select the Jamba model from hugging Face Hub using the following step:
model_id = "ai21labs/Jamba-v0.1"Import Required Libraries/Classes
from datasets import load_dataset
from trl import SFTTrainer
from peft import LoraConfig
from transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArguments, BitsAndBytesConfigNow represent the model’s weights with fewer bits (4 bits in our case)
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
llm_int4_skip_modules=["mamba"]
)Load Model and tokenizer:
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
trust_remote_code=True,
device_map='auto',
attn_implementation="flash_attention_2",
quantization_config=quantization_config,
use_mamba_kernels=False #Disabling the mamba kernels since I have a recurrent error.
)Save model and tokenizer in Google Drive if you want:
model.save_pretrained("/content/drive/MyDrive/jamba")
tokenizer.save_pretrained("/content/drive/MyDrive/jamba")Now Load the English Quotes dataset from hugging face using datasets library.
! pip install datasetsdataset = load_dataset("Abirate/english_quotes", split="train")Set required parameters
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=4,
logging_dir='./logs',
logging_steps=10,
learning_rate=2e-3 # 2.5e-5
)Lora Configuration:
lora_config = LoraConfig(
r=8,
target_modules=["embed_tokens", "x_proj", "in_proj", "out_proj"],
task_type="CAUSAL_LM",
bias="none"
)Start Fine-tuning:
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
args=training_args,
peft_config=lora_config,
train_dataset=dataset,
dataset_text_field="quote",
max_seq_length=256
)
trainer.train()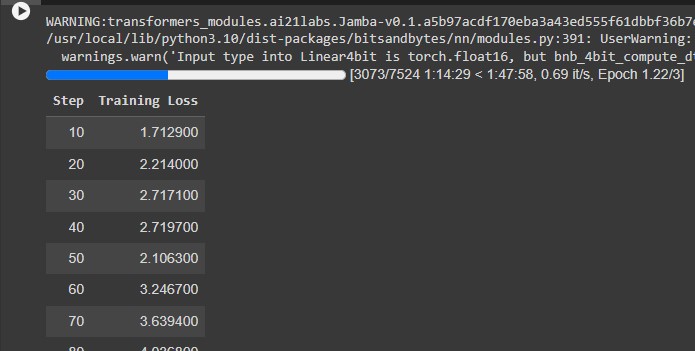
It’s Done 🤗.
Other Related Methods to Use Jamba (Optional)
Loading the base model in half-precision
The published checkpoint is saved in BF16. To load it into RAM in BF16/FP16, you need to specify the torch_dtype:
from transformers import AutoModelForCausalLM
import torch
model = AutoModelForCausalLM.from_pretrained("ai21labs/Jamba-v0.1",
trust_remote_code=True,
torch_dtype=torch.bfloat16) # you can also use torch_dtype=torch.float16When using half-precision, enable FlashAttention2 for Attention blocks. Ensure the model is on a CUDA device. If the model is too large for a single 80GB GPU, parallelize it using accelerate.
from transformers import AutoModelForCausalLM
import torch
model = AutoModelForCausalLM.from_pretrained("ai21labs/Jamba-v0.1",
trust_remote_code=True,
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
device_map="auto")Load the model in 8-bit
A single 80GB GPU can accommodate up to 140K sequence lengths with 8-bit precision. Bitsandbytes simplifies the process of quantizing the model to 8 bits. To maintain the quality of the model, we recommend excluding the Mamba blocks from the quantization process:
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(load_in_8bit=True,
llm_int8_skip_modules=["mamba"])
model = AutoModelForCausalLM.from_pretrained("ai21labs/Jamba-v0.1",
trust_remote_code=True,
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
quantization_config=quantization_config)Notice
Jamba is a base model intended to serve as a foundation for custom solution development, training, and fine-tuning. It’s important to add guardrails for responsible and safe use, as Jamba lacks safety moderation mechanisms.