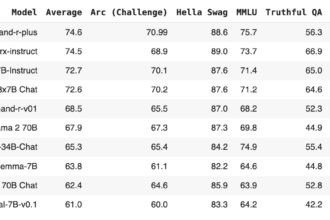
Meta introduced the Meta Llama 3 family of LLMs, comprising pre-trained and instruction-tuned generative text models in 8 and 70B sizes. These instruction-tuned models are optimized for dialogue, outperforming many open-source chat models on industry benchmarks. Careful attention was given to optimizing helpfulness and safety during development.
Fine-tuning
Fine-tuning is a technique used in machine learning, particularly with large language models (LLMs). It’s a way to take advantage of an existing model’s knowledge and tailor it for a specific task. Here’s a breakdown:
- Imagine a pre-trained model like me, trained on a massive amount of text data. I can understand and respond to language generally, but not necessarily for a specific purpose.
- Fine-tuning comes in when you want to specialize me for a certain task. You provide a smaller dataset of data relevant to your task, and the model fine-tunes its internal parameters based on this new information.
- Think of it like this: I’ve learned the basics of many subjects in school. Fine-tuning is like taking an intensive course in a specific subject, allowing me to become an expert in that area.
🔻Fine-tuning with Unsloth
Start Fine-tuning Llama-3 8B with Unsloth
Step 1: Install Libraries
%%capture
import torch
major_version, minor_version = torch.cuda.get_device_capability()
# Must install separately since Colab has torch 2.2.1, which breaks packages
!pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"
if major_version >= 8:
# Use this for new GPUs like Ampere, Hopper GPUs (RTX 30xx, RTX 40xx, A100, H100, L40)
!pip install --no-deps packaging ninja einops flash-attn xformers trl peft accelerate bitsandbytes
else:
# Use this for older GPUs (V100, Tesla T4, RTX 20xx)
!pip install --no-deps xformers trl peft accelerate bitsandbytes
passStep 2: Import Libraries & Load Model
from unsloth import FastLanguageModel
import torch
max_seq_length = 2048
dtype = None
load_in_4bit = True
fourbit_models = [
"unsloth/mistral-7b-bnb-4bit",
"unsloth/mistral-7b-instruct-v0.2-bnb-4bit",
"unsloth/llama-2-7b-bnb-4bit",
"unsloth/gemma-7b-bnb-4bit",
"unsloth/gemma-7b-it-bnb-4bit",
"unsloth/gemma-2b-bnb-4bit",
"unsloth/gemma-2b-it-bnb-4bit",
"unsloth/llama-3-8b-bnb-4bit",
] # More models at https://huggingface.co/unsloth
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/llama-3-8b-bnb-4bit",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
# token = "hf_...", # use one if using gated models like meta-llama/Llama-2-7b-hf
)Step 3: LoRA adapters
model = FastLanguageModel.get_peft_model(
model,
r = 16, # Choose any number > 0 ! Suggested 8, 16, 32, 64, 128
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",],
lora_alpha = 16,
lora_dropout = 0, # Supports any, but = 0 is optimized
bias = "none", # Supports any, but = "none" is optimized
# [NEW] "unsloth" uses 30% less VRAM, fits 2x larger batch sizes!
use_gradient_checkpointing = "unsloth", # True or "unsloth" for very long context
random_state = 3407,
use_rslora = False, # It support rank stabilized LoRA
loftq_config = None, # And LoftQ
)Step 4: Set Format & Load Dataset
alpaca_prompt = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{}
### Input:
{}
### Response:
{}"""
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
instructions = examples["instruction"]
inputs = examples["input"]
outputs = examples["output"]
texts = []
for instruction, input, output in zip(instructions, inputs, outputs):
# Must add EOS_TOKEN, otherwise your generation will go on forever!
text = alpaca_prompt.format(instruction, input, output) + EOS_TOKEN
texts.append(text)
return { "text" : texts, }
pass
from datasets import load_dataset
dataset = load_dataset("yahma/alpaca-cleaned", split = "train")
dataset = dataset.map(formatting_prompts_func, batched = True,)Step 5: let’s use Huggingface TRL’s SFTTrainer
from trl import SFTTrainer
from transformers import TrainingArguments
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset,
dataset_text_field = "text",
max_seq_length = max_seq_length,
dataset_num_proc = 2,
packing = False, # Can make training 5x faster for short sequences.
args = TrainingArguments(
per_device_train_batch_size = 2,
gradient_accumulation_steps = 4,
warmup_steps = 5,
max_steps = 60,
learning_rate = 2e-4,
fp16 = not torch.cuda.is_bf16_supported(),
bf16 = torch.cuda.is_bf16_supported(),
logging_steps = 1,
optim = "adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 3407,
output_dir = "outputs",
),
)Step 6: Train the model
trainer_stats = trainer.train()Step 7: Let’s run the model
# alpaca_prompt = Copied from above
FastLanguageModel.for_inference(model) # Enable native 2x faster inference
inputs = tokenizer(
[
alpaca_prompt.format(
"Continue the fibonnaci sequence.", # instruction
"1, 1, 2, 3, 5, 8", # input
"", # output - leave this blank for generation!
)
], return_tensors = "pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens = 64, use_cache = True)
tokenizer.batch_decode(outputs)Step 8: Save the model
model.save_pretrained("lora_model") # Local saving
# model.push_to_hub("your_name/lora_model", token = "...") # Online savingColab Notebook: Alpaca + Llama-3 8b full example.ipynb
🔻Fine-tuning with ORPO
Fine-tune Llama 3 with ORPO
ORPO needs preference data (prompt, chosen & rejected answer). We’ll use mlabonne/orpo-dpo-mix-40k (combines high-quality DPO datasets).
This condenses the text while maintaining all the essential information.
As per usual, let’s start by installing the required libraries.
!pip install -U transformers datasets accelerate peft trl bitsandbytes wandbFor recent GPUs, consider Flash Attention for efficient inference.
import gc
import os
import torch
import wandb
from datasets import load_dataset
from google.colab import userdata
from peft import LoraConfig, PeftModel, prepare_model_for_kbit_training
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
TrainingArguments,
pipeline,
)
from trl import ORPOConfig, ORPOTrainer, setup_chat_format
wb_token = userdata.get('wandb')
wandb.login(key=wb_token)For those with recent GPUs, utilizing the Flash Attention library can enhance performance by replacing the default eager attention implementation.
if torch.cuda.get_device_capability()[0] >= 8:
!pip install -qqq flash-attn
attn_implementation = "flash_attention_2"
torch_dtype = torch.bfloat16
else:
attn_implementation = "eager"
torch_dtype = torch.float16Additionally, I’m utilizing the convenient setup_chat_format() function to tailor the model and tokenizer for ChatML support. This function automates the application of a chat template, inclusion of special tokens, and adjustment of the model’s embedding layer to match the new vocabulary size.
# Model
base_model = "meta-llama/Meta-Llama-3-8B"
new_model = "OrpoLlama-3-8B"
# QLoRA config
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch_dtype,
bnb_4bit_use_double_quant=True,
)
# LoRA config
peft_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules=['up_proj', 'down_proj', 'gate_proj', 'k_proj', 'q_proj', 'v_proj', 'o_proj']
)
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(base_model)
# Load model
model = AutoModelForCausalLM.from_pretrained(
base_model,
quantization_config=bnb_config,
device_map="auto",
attn_implementation=attn_implementation
)
model, tokenizer = setup_chat_format(model, tokenizer)
model = prepare_model_for_kbit_training(model)With the model prepared for training, let’s address the dataset. We’ll load mlabonne/orpo-dpo-mix-40k and utilize the apply_chat_template() function to transform the “chosen” and “rejected” columns into the ChatML format. It’s worth noting that I’m opting for just 1,000 samples from the dataset, as processing the entire dataset would be time-consuming.
dataset_name = "mlabonne/orpo-dpo-mix-40k"
dataset = load_dataset(dataset_name, split="all")
dataset = dataset.shuffle(seed=42).select(range(10))
def format_chat_template(row):
row["chosen"] = tokenizer.apply_chat_template(row["chosen"], tokenize=False)
row["rejected"] = tokenizer.apply_chat_template(row["rejected"], tokenize=False)
return row
dataset = dataset.map(
format_chat_template,
num_proc= os.cpu_count(),
)
dataset = dataset.train_test_split(test_size=0.01)Before proceeding to training, let’s establish some essential hyperparameters:
- learning_rate: ORPO typically employs considerably lower learning rates compared to traditional SFT or DPO. The value of 8e-6 is drawn from the original paper, roughly corresponding to an SFT learning rate of 1e-5 and a DPO learning rate of 5e-6. It’s advisable to experiment with adjustments, perhaps increasing it to around 1e-6 for a more refined fine-tuning process.
- beta: This parameter, denoted as $\lambda$ in the paper, has a default value of 0.1. An appendix in the original paper details its selection through an ablation study.
- Other parameters such as max_length and batch size are configured to utilize as much VRAM as available, approximately 20 GB in this setup.
- Ideally, the model would undergo training for 3-5 epochs, but for brevity, we’ll limit it to 1 epoch here.
With these parameters established, we can proceed to train the model using the ORPOTrainer, which serves as a wrapper for the training process.
orpo_args = ORPOConfig(
learning_rate=8e-6,
beta=0.1,
lr_scheduler_type="linear",
max_length=1024,
max_prompt_length=512,
per_device_train_batch_size=2,
per_device_eval_batch_size=2,
gradient_accumulation_steps=4,
optim="paged_adamw_8bit",
num_train_epochs=1,
evaluation_strategy="steps",
eval_steps=0.2,
logging_steps=1,
warmup_steps=10,
report_to="wandb",
output_dir="./results/",
)
trainer = ORPOTrainer(
model=model,
args=orpo_args,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
peft_config=peft_config,
tokenizer=tokenizer,
)
trainer.train()
trainer.save_model(new_model)Wrapping up this tutorial, we’ll merge the QLoRA adapter with the base model and then push it to the Hugging Face Hub for sharing and collaboration.
# Flush memory
del trainer, model
gc.collect()
torch.cuda.empty_cache()
# Reload tokenizer and model
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForCausalLM.from_pretrained(
base_model,
low_cpu_mem_usage=True,
return_dict=True,
torch_dtype=torch.float16,
device_map="auto",
)
model, tokenizer = setup_chat_format(model, tokenizer)
# Merge adapter with base model
model = PeftModel.from_pretrained(model, new_model)
model = model.merge_and_unload()
model.push_to_hub(new_model, use_temp_dir=False)
tokenizer.push_to_hub(new_model, use_temp_dir=False)Colab Notebook: ZeroChat.ipynb
| Model | Average | AGIEval | GPT4All | TruthfulQA | Bigbench |
|---|---|---|---|---|---|
| meta-llama/Meta-Llama-3-8B-Instruct 📄 | 51.34 | 41.22 | 69.86 | 51.65 | 42.64 |
| mlabonne/OrpoLlama-3-8B 📄 | 46.76 | 31.56 | 70.19 | 48.11 | 37.17 |
| meta-llama/Meta-Llama-3-8B 📄 | 45.42 | 31.1 | 69.95 | 43.91 | 36.7 |
🔻Fine-tuning with medical chatbot dataset
Dataset: https://huggingface.co/datasets/ruslanmv/ai-medical-chatbotComing Soon 🔜
I am currently working on it but facing a CUDA error. Hopefully, it will be resolved soon.
Here’s the Colab Notebook: https://colab.research.google.com/drive/1TUa9J2J_1Sj-G7mQHX45fKzZtnW3s1vj?usp=sharing
Let’s Wrap
key advantages of fine-tuning:
- Faster Training: Pre-trained models have already learned general features from massive datasets. Fine-tuning leverages this knowledge, allowing your model to grasp your specific task much quicker.
- Reduced Data Requirements: Large amounts of labeled data are often needed to train complex models. Fine-tuning can achieve good results even with limited data for your specific task, as the pre-trained model provides a strong foundation.
- Improved Performance: By transferring knowledge from a well-performing pre-trained model, fine-tuning can often lead to better accuracy on your target task compared to training from scratch.