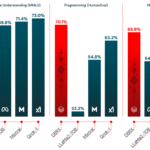
C4AI Command R+ (CohereForAI/c4ai-command-r-plus) is the latest large language model that beats all other LLMs on the Hugging Face’s open LLM leaderboard.
It’s an open-source weight research release of 104 billion parameters, including Retrieval Augmented Generation (RAG) and tools used to automate sophisticated tasks. It’s evaluated in 10 languages for performance: English, French, Italian, Spanish, German, Japanese, Korean, Brazilian Portuguese, Arabic, and Simplified Chinese.
This model is optimized for conversational interaction and long-context tasks, with a maximum context length of 128K.
Model Architecture
This language model is auto-regressive and makes use of an ideal Transformer architecture. The model uses preference training and supervised fine-tuning after pretraining to match model behavior to human preferences for safety and helpfulness.
Key Points
Here are the key points about Command R+:
- Purpose and Use Cases:
- Command R+ is intended for intricate tasks requiring the use of multi-step tools or agents and retrieval augmented generation (RAG) functionality. It performs best in scenarios that demand complex interactions and longer contexts.
- Capabilities:
- Language Tasks: Command R+ has been trained on a wide range of texts in several languages, enabling it to excel in various text-generation tasks.
- Fine Tuning Use-Cases: It has been specifically fine-tuned to excel in critical domain use cases.
- Multilingual Support: Performs well in 10 languages.
- Cross-Lingual Tasks: It is capable of handling cross-lingual tasks such as content translation and multilingual question answering.
- Grounded Generations:
- Command R+ can ground its English-speaking generations. This means that it can produce responses with citations indicating the information’s source based on a list of provided document snippets.
- Fine-Tuning and Safety:
- Its architecture is based on an optimized transformer design, and its outputs have been tuned via supervised and preference training to match human preferences for safety and helpfulness.
- For multi-step tool usage, developers can link Command R+ to external tools (search engines, APIs, etc.).
Evaluations
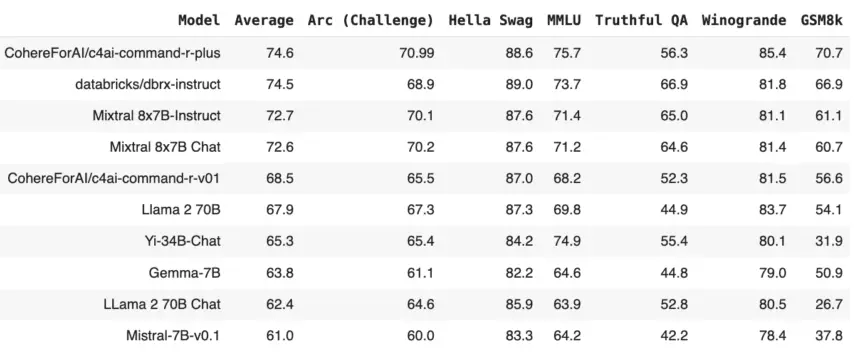
Along with a direct comparison to the most robust state-of-the-art open weights models currently on Hugging Face, we present the results below. It should be noted that these results are intended solely for comparison with other models submitted to the leaderboard or with self-reported data, which may not be reproducible in the same manner. Evaluations for all models should be conducted using standardized methods with publicly available code.
| Model | Average | Arc (Challenge) | Hella Swag | MMLU | Truthful QA | Winogrande | GSM8k |
|---|---|---|---|---|---|---|---|
| CohereForAI/c4ai-command-r-plus | 74.6 | 70.99 | 88.6 | 75.7 | 56.3 | 85.4 | 70.7 |
| DBRX Instruct | 74.5 | 68.9 | 89 | 73.7 | 66.9 | 81.8 | 66.9 |
| Mixtral 8x7B-Instruct | 72.7 | 70.1 | 87.6 | 71.4 | 65 | 81.1 | 61.1 |
| Mixtral 8x7B Chat | 72.6 | 70.2 | 87.6 | 71.2 | 64.6 | 81.4 | 60.7 |
| CohereForAI/c4ai-command-r-v01 | 68.5 | 65.5 | 87 | 68.2 | 52.3 | 81.5 | 56.6 |
| Llama 2 70B | 67.9 | 67.3 | 87.3 | 69.8 | 44.9 | 83.7 | 54.1 |
How to Use C4AI Command R+
To Use this model you first need to install transformers. Use the following command to install:
! pip install transformersNow, load the model directly from Hugging Face Hub.
model_id = "CohereForAI/c4ai-command-r-plus"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id)Message format for C4AI Command R+:
# Format message with the command-r-plus chat template
## <BOS_TOKEN><|START_OF_TURN_TOKEN|><|USER_TOKEN|>How to Fine Tune C4AI Command R+?<|END_OF_TURN_TOKEN|><|START_OF_TURN_TOKEN|><|CHATBOT_TOKEN|>messages = [{"role": "user", "content": "How to Fine Tune C4AI Command R+?"}]
input_ids = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt")Set the Required Parameters and get output:
gen_tokens = model.generate(
input_ids,
max_new_tokens=100,
do_sample=True,
temperature=0.3,
)
gen_text = tokenizer.decode(gen_tokens[0])
print(gen_text)Additional: To quantize the model through bitsandbytes, 8-bit precision.
# pip install 'git+https://github.com/huggingface/transformers.git' bitsandbytes accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
bnb_config = BitsAndBytesConfig(load_in_8bit=True)
model_id = "CohereForAI/c4ai-command-r-plus"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=bnb_config)
# Format message with the command-r-plus chat template
messages = [{"role": "user", "content": "Hello, how are you?"}]
input_ids = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt")
## <BOS_TOKEN><|START_OF_TURN_TOKEN|><|USER_TOKEN|>Hello, how are you?<|END_OF_TURN_TOKEN|><|START_OF_TURN_TOKEN|><|CHATBOT_TOKEN|>
gen_tokens = model.generate(
input_ids,
max_new_tokens=100,
do_sample=True,
temperature=0.3,
)
gen_text = tokenizer.decode(gen_tokens[0])
print(gen_text)Tool use & multihop capabilities:
Command R+ has undergone specialized training in the use of conversational tools. This involved employing a specific prompt template and applying a combination of supervised and preference fine-tuning techniques to integrate these tools into the model. We strongly encourage experimentation, but deviating from this prompt template may result in decreased performance.
Usage: Rendering Tool Use Prompts.
from transformers import AutoTokenizer
model_id = "CohereForAI/c4ai-command-r-plus"
tokenizer = AutoTokenizer.from_pretrained(model_id)
# define conversation input:
conversation = [
{"role": "user", "content": "Whats the biggest penguin in the world?"}
]
# Define tools available for the model to use:
tools = [
{
"name": "internet_search",
"description": "Returns a list of relevant document snippets for a textual query retrieved from the internet",
"parameter_definitions": {
"query": {
"description": "Query to search the internet with",
"type": 'str',
"required": True
}
}
},
{
'name': "directly_answer",
"description": "Calls a standard (un-augmented) AI chatbot to generate a response given the conversation history",
'parameter_definitions': {}
}
]
# render the tool use prompt as a string:
tool_use_prompt = tokenizer.apply_tool_use_template(
conversation,
tools=tools,
tokenize=False,
add_generation_prompt=True,
)
print(tool_use_prompt)Grounded Generation and RAG Capabilities:
Command R+ has undergone specialized training in grounded generation, enabling it to generate responses using a provided list of document excerpts. These responses include grounding spans (citations) indicating the original source of information. This capability can support behaviors such as the last phase of retrieval augmented generation (RAG) and grounded summarization. Through the application of a specific prompt template and a combination of supervised and preference fine-tuning, this behavior has been ingrained into the model. While we encourage experimentation, it’s important to note that deviating from this prompt template may lead to a decrease in performance.
Usage: Rendering Grounded Generation prompts.
from transformers import AutoTokenizer
model_id = "CohereForAI/c4ai-command-r-plus"
tokenizer = AutoTokenizer.from_pretrained(model_id)
# define conversation input:
conversation = [
{"role": "user", "content": "Whats the biggest penguin in the world?"}
]
# define documents to ground on:
documents = [
{ "title": "Tall penguins", "text": "Emperor penguins are the tallest growing up to 122 cm in height." },
{ "title": "Penguin habitats", "text": "Emperor penguins only live in Antarctica."}
]
# render the tool use prompt as a string:
grounded_generation_prompt = tokenizer.apply_grounded_generation_template(
conversation,
documents=documents,
citation_mode="accurate", # or "fast"
tokenize=False,
add_generation_prompt=True,
)
print(grounded_generation_prompt)Code Capabilities
To interact effectively with your code, Command R+ has been optimized to request code snippets, code explanations, or code rewrites. It may not perform optimally for pure code completion without further adjustments.