SDXL-Lightning models are a set of text-to-image generation models distilled using a diffusion distillation method, aiming to achieve a new state-of-the-art in one-step/few-step 1024px image generation based on SDXL.
These models are distilled from Hugging Face stabilityai/stable-diffusion-xl-base-1.0. This repository contains checkpoints for 1-step, 2-step, 4-step, and 8-step distilled models. The image generation for 2-step, 4-step and 8-step models have amazing quality. However 1-step model is more experimental.
Both full UNet and LoRA checkpoints are included in the model. The LoRA models can be used with other base models, but the full UNet models are superior.
- Generate with all configurations on Hugging Face, best quality: Demo
- Real-time generation as you type, lightning-fast: Demo from fastsdxl.ai
- Image Generation with Customization Features: Replicate Playground
Using SDXL-Lightning enables the generation of exceptionally high-quality images in a single step.
For more information, please refer to the research paper: SDXL-Lightning: Progressive Adversarial Diffusion Distillation. This open-source model available as part of the research.
Diffusion models, generative models, have advanced applications in text-to-image and video. However, their generation process is slow and computationally demanding. To accelerate high-quality samples, researchers are exploring methods like SDXL-Lightning, which combines progressive and adversarial distillation for fewer inference steps. The approach combines progressive and adversarial distillation, ensuring a balance between quality and mode coverage.
In this article, I will show you how to use SDXL Lightning to generate high quality images.
SDXL-Lightning: Speed and Quality Combined in Just 2 Steps
SDXL-Lightning is a new text-to-image generation model created by researchers at ByteDance, to generate high quality images. The method employs Progressive Adversarial Diffusion Distillation, which enables the fast creation of high-resolution (1024px) images in a few steps. The model has been open-sourced for research and provides a range of configurations and checkpoints for different inference steps.
ByteDance, the parent company of TikTok, has released SDXL Lightning weights, which means they are not directly linked to stability.ai! Its optimization for 1024x1024px makes it appear to produce better results than SDXL Turbo and LCM models.
Key Features
- Fast Generation: Has the ability to quickly produce high quality images.
- Progressive Adversarial Diffusion Distillation: Uses modern technology to convert written text into images.
- Open Source: Models and checkpoints are open for public use and experimentation.
How to use SDXL-Lightning text-to-image Generation with Transformers
To use SDXL-Lightning models with transformers, make sure to use the latest transformers release. To install latest version of transformers run following command in notebook. You can also use terminal for this purpose.
! pip install -U "transformers==4.38.1" --upgradeNext Step is to install diffusers.
! pip install diffusersNow import required libraries, classes & function using following python code snippets.
import torch
from diffusers import StableDiffusionXLPipeline, UNet2DConditionModel, EulerDiscreteScheduler
from huggingface_hub import hf_hub_download
from safetensors.torch import load_fileByteDance/SDXL-Lightning provides a complete range of model weights to download and includes supplementary information for each file in the model card. There are several options: LORAs, UNETs and Base Models with 1, 2, 4, or 8 step. I will focus on the 4-phase UNET model in the following sections.
After importing, the next step is to select the specific model that is required for download. You can also use any different ckpt if required. The list of other ckpt are available here.
base = "stabilityai/stable-diffusion-xl-base-1.0"
repo = "ByteDance/SDXL-Lightning"
ckpt = "sdxl_lightning_4step_unet.safetensors"Now load your downloaded model.
unet = UNet2DConditionModel.from_config(base, subfolder="unet").to("cuda", torch.float16)
unet.load_state_dict(load_file(hf_hub_download(repo, ckpt), device="cuda"))
pipe = StableDiffusionXLPipeline.from_pretrained(base, unet=unet, torch_dtype=torch.float16, variant="fp16").to("cuda")
# Ensure sampler uses "trailing" timesteps.
pipe.scheduler = EulerDiscreteScheduler.from_config(pipe.scheduler.config, timestep_spacing="trailing")Well done! 👍 Now, your model is ready for use. Specify a prompt for the image you want to create and add a file name to it.
pipe("A Panda Playing with football", num_inference_steps=4, guidance_scale=0).images[0].save("image_name.png")Use this additional step if you want to view output on your notebook.
from IPython.display import Image
Image("image_name.png")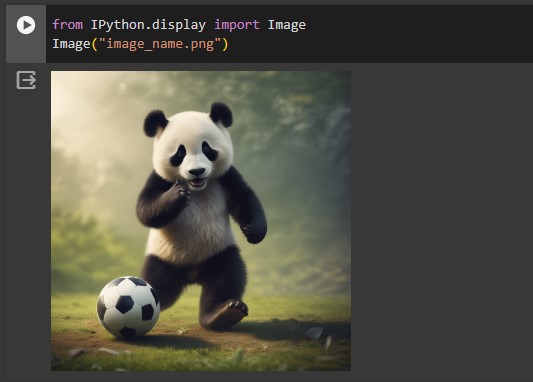
Check the Google Colab notebook for the previous steps here.
2-Step, 4-Step, 8-Step LoRA
If you are using non-SDXL base models then use LoRA only. Otherwise use the UNet checkpoint for better quality.
import torch
from diffusers import StableDiffusionXLPipeline, EulerDiscreteScheduler
from huggingface_hub import hf_hub_download
base = "stabilityai/stable-diffusion-xl-base-1.0"
repo = "ByteDance/SDXL-Lightning"
ckpt = "sdxl_lightning_4step_lora.safetensors" # Use the correct ckpt for your step setting!
# Load model.
pipe = StableDiffusionXLPipeline.from_pretrained(base, torch_dtype=torch.float16, variant="fp16").to("cuda")
pipe.load_lora_weights(hf_hub_download(repo, ckpt))
pipe.fuse_lora()
# Ensure sampler uses "trailing" timesteps.
pipe.scheduler = EulerDiscreteScheduler.from_config(pipe.scheduler.config, timestep_spacing="trailing")
# Ensure using the same inference steps as the loaded model and CFG set to 0.
pipe("A panda smiling", num_inference_steps=4, guidance_scale=0).images[0].save("output.png")1-Step UNet
The 1-step model is an experimental approach, but its stability is significantly reduced. The 2-step method is a more effective option for better quality.
In the 1-step model, “sample” is used to predict everything better than “epsilon” (which doesn’t work better in this situation). The scheduler needs to be configured correctly.
import torch
from diffusers import StableDiffusionXLPipeline, UNet2DConditionModel, EulerDiscreteScheduler
from huggingface_hub import hf_hub_download
from safetensors.torch import load_file
base = "stabilityai/stable-diffusion-xl-base-1.0"
repo = "ByteDance/SDXL-Lightning"
ckpt = "sdxl_lightning_1step_unet_x0.safetensors" # Use the correct ckpt for your step setting!
# Load model.
unet = UNet2DConditionModel.from_config(base, subfolder="unet").to("cuda", torch.float16)
unet.load_state_dict(load_file(hf_hub_download(repo, ckpt), device="cuda"))
pipe = StableDiffusionXLPipeline.from_pretrained(base, unet=unet, torch_dtype=torch.float16, variant="fp16").to("cuda")
# Ensure sampler uses "trailing" timesteps and "sample" prediction type.
pipe.scheduler = EulerDiscreteScheduler.from_config(pipe.scheduler.config, timestep_spacing="trailing", prediction_type="sample")
# Ensure using the same inference steps as the loaded model and CFG set to 0.
pipe("A panda playing with football", num_inference_steps=1, guidance_scale=0).images[0].save("output.png")FAQ’s
8step vs 4step which one more realistic photo?
More step is better quality.
Whay to download/use LoRA?
If you opt for the entire UNet, there’s no necessity to download LoRA. It’s for if you want to use some community finetuned SDXL base model.
Does this model support 512 resolution?
This is a derivative of the SDXL model, which typically begins at 1024px. Therefore, I have reservations about its support for 512px. For a resolution of 512×512, consider using SDXL-Turbo directly from Stability AI.
How to finetune lightning model or create my own version?
Suggestion:
- Train the regular SDXL model on your dataset, and then apply SDXL-Lightning LoRA on top for acceleration.
- Preferably, train SDXL using LoRA as well, ensuring minimal model changes for optimal compatibility.
More advanced:
- If the quality is not satisfactory, consider merging SDXL-Lightning LoRA with your model and then training on top. However, using MSE loss may diminish the acceleration effect.
- For the most advanced approach, merge SDXL-Lightning LoRA and employ an adversarial objective, similar to what the SDXL-Lightning paper demonstrates.
Can’t load the model files. The same error whether it is 4 or 8.
Error occurred when executing CheckpointLoaderSimple:
‘model.diffusion_model.input_blocks.0.0.weight’
You probably downloaded the wrong weight.
Use:sdxl_lightning_4step.safetensors
Not:sdxl_lightning_4step_lora.safetensorssdxl_lightning_4step_unet.safetensors