The rapid evolution of large language models (LLMs) is captivating the Generative AI industry, with enterprises not only interested but obsessed with integrating this advanced technology into their operations. Billions of dollars have been invested in LLM research and development. With even more money likely on the way, industry leaders and AI experts are clamouring to utilize these models.
These models are trained on massively large text datasets and have become state-of-the-art at tasks such as text generation, translation, summarisation, question-answering, and other natural language processing (NLP) tasks. However, despite their advanced capabilities, LLMs may not always align with specific tasks or domains.
Fine-tuning allows previously trained LLMs to adapt to more specified tasks. This blog highlights how fine-tuning LLMs can significantly increase model performance, lower training costs and yield context-specific results.
What is Fine-tuning?
Fine-tuning is a technique used in machine learning, specifically deep learning, whereby a pre-trained model is further trained on a custom dataset to do a specific task. It can be performed on the entire neural network or specific layers. This technique is useful when you have a pre-trained model that is trained on a large dataset and can’t perform well on your domain-specific task.
Training a new model from scratch can be computationally expensive and time-consuming. Fine-tuning allows you to leverage the knowledge that the pre-trained model learned in the initial training phase on a large dataset.
Here’s a breakdown of how it works:
- Pre-trained Model: Imagine a powerful language model that was trained on a large amount of text data, making it adept at grasping language knowledge and patterns.
- Fine-Tuning: Now, let’s say you don’t want to invest in a model from scratch and want to use an LLM who is an expert at writing different kinds of creative content. Through fine-tuning, you’d need to train the model for language patterns and creative writing. You simply need a dataset that you have to provide to the model and the model expertise will extend toward your specific task.
- Adaptation: By providing your data to a pre-trained model you can start fine-tuning its internal parameters, which are like dials that control its decision-making process.
Types of fine-tuning
There are five main types of fine-tuning LLMs:
1. Supervised Fine-Tuning (SFT)
This is the most common approach used in fine-tuning in which the pre-trained model is provided a labeled data sets specific to the desired task.
Imagine you want to fine-tune an LLM for sentiment analysis. You have to provide a labelled dataset containing texts and their corresponding labels, such as positive, negative, or neutral. The LLM analyzes this data and become proficient in analyzing sentiments.
2. Reinforcement Learning from Human Feedback (RLHF)
Reinforcement learning is a recent technique for fine-tuning that is based on human feedback. Here’s the basic idea:
The LLM generates an output and humans give a feedback on whether the output meets the requirements or not. Using this feedback, the LLM undergoes an iterative learning process to improve its performance on that task.
3. Transfer learning
Transfer learning is a broad concept in machine learning, which involves using previously trained models for new, related tasks.
- Fine-tuning is a specific category within transfer learning, which focuses on enabling a model to perform different tasks than it was initially trained to do.
- It works by using knowledge gained from a large, general dataset and applying it to more specific or domain-related tasks.
- This add an extra layer of expertise to the transfer learning process.
Transfer learning can be viewed as a form of supervised fine-tuning.
4. Domain-specific fine-tuning
Fine-tuning language models involve making them understand and generate domain-specific text, and increasing proficiency by training on data from the target domain. A direct approach to fine-tuning is training the model with data directly related to the target task. By doing so, it makes models capable of accommodating idiosyncrasies inherent in any given task and thus improves its performance as well as relevance. Task-specific fine-tuning aims at optimizing performance for specific tasks that are well defined leading to accuracy. This supplements transfer learning, in which a model is adapted to fulfill specific duties.
5. Few-shot learning
In real-world scenarios, collecting a large amount of data is impractical or costly. Few-shot learning helps us to overcome this by learning from just few examples. It’s a pivotal technique in machine learning, allowing using a pre-trained model and make litle adjustments with limited task-specific data.
A Step-by-Step Guide to Fine-tuning a LLM
We already know that Fine-tuning is updating a pre-trained model’s parameters by training on your task specific dataset. Therefore, we can exemplify this concept through fine tuning an actual model.
We will use all the main techniques (PEFT, LoRA & TRL) of fine-tuning to fine-tune the modeld such as T5, BERT, GPT-2 which serve as the base for fine-tuning. By learning all these methods on these model you will be expert and can easily fine-tune any type of transformer-based model.
Now let us practicall look at some interesting techniques used in the process of finetuning.
1. Fine-Tuning GPT-2 for beginners
In this tutorial, we will use the GPT-2 model, which is available on Hugging Face, and fine-tune it for sentiment analysis without any specific method.
Step 1: Choose a pre-trained model and a dataset
In order to train the model, we always need a pre-trained model. Imagine we are using GPT-2 model for sentiment analysis, but it’s not able to properly detect the sentiments. Now, to improve accuracy, we will fine-tune it on Twitter dataset which has tweets and their corresponding sentiment, to train our model.
Step 2: Load Dataset
As we are going to fine-tune using transformers, So first we have to install transformers library:
! pip install transformers datasets pandas evaluate accelerateNow that we have our model, what we need is a quality dataset. I would use the Hugging Face datasets library to import a dataset containing tweets segmented by their sentiment (Positive, Neutral or Negative).
from datasets import load_dataset
import pandas as pd
# To Load Dataset
dataset = load_dataset("mteb/tweet_sentiment_extraction")
# To Check Dataset
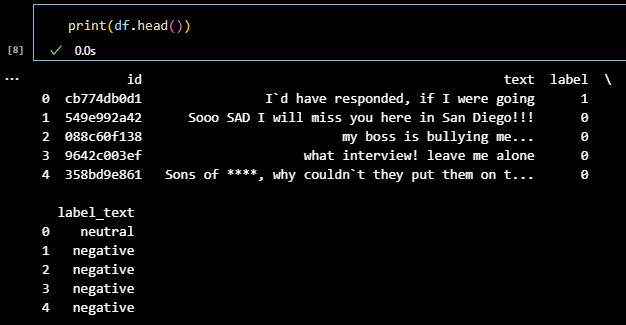
df = pd.DataFrame(dataset['train'])
print(df.head())If you look at the dataset that you just downloaded it has got one portion for training and one for testing. When converted to a dataframe, the training subset appears as follows.
Step 3: Tokenizer
As our dataset is ready, now we need a tokenizer to make it ready for parsing by the model.
To process the dataset, we need a tokenizer because LLMs operate using tokens. Apply a preprocessing function to the whole dataset using the Datasets map method to treat it all in one step.
from transformers import GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
tokenizer.pad_token = tokenizer.eos_token
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)We can refine our model by creating a smaller subset of the entire dataset, which will improve our processing requirements. Once our model is fine using the training set, we can validate it using the testing set.
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))Step 4: Initialize base model
Start by loading your model and specifying the expected number of labels. From the sentiment dataset card of tweets, you know that there are three labels:
from transformers import GPT2ForSequenceClassification
model = GPT2ForSequenceClassification.from_pretrained("gpt2", num_labels=3)Step 5: Evaluate method
Transformers provides a suitable trainer class for training. However, this methodology does not include how to evaluate the model. So, before starting our training, we should pass a function to the trainer to evaluate the performance of our model.
import evaluate
metric = evaluate.load("accuracy")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)Step 6: Fine-tune using the Trainer Method
The final step is to set the training arguments and start the training process. The Trainer class, which is included in the Transformers library, supports a variety of training options and features such as gradient summation, mixed precision, and logging. Initially, we explain the evaluation approach and the training arguments. Once everything is defined, we can use the train() command to train the model efficiently.
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
output_dir="test_trainer",
#evaluation_strategy="epoch",
per_device_train_batch_size=1, # Reduce batch size here
per_device_eval_batch_size=1, # Optionally, reduce for evaluation as well
gradient_accumulation_steps=4
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset,
compute_metrics=compute_metrics,
)
trainer.train()Analyze the model’s performance using a validation or test set once it has been trained. Once more, this is already handled by the evaluate method in the trainer class.
import evaluate
trainer.evaluate()This is easiest method to fine-tune any LLM. Keep in mind that fine-tuning LLM requires a lot of processing power, which your local machine may not have.
2. Parameter Efficient Fine-Tuning (PEFT)
PEFT is one of the most commonly used method in fine-tuning that is much more efficient. Training or Fine-tuning a language model required a high computation power and memory. PEFT provides a solution to this problem by updating only a subset of parameters, effectively “freezing” the rest. This method helps us to effectively manage our memory and processing power. PEFT might involve adding new layers or modifying existing ones specifically for the task, rather than retraining the entire model.
We are going to use bert base model for this tuning that was available on Hugging Face. This is a model by google having 110M parameters that was trained on 3.3 Billion words, with 2.5B from Wikipedia and 0.8B from BooksCorpus.
We are going to fine-tune, bert-base-uncased to recognize disease names based on symptoms. When we check the accuracy of on gretelai/symptom_to_diagnosis dataset, the accuracy is 4.25%.
Looks like very poor performance. Let’s see if we able to get better results by using the training data to build a fine-tuned model to predict diagnosis with the given text description of symptoms as input.
Step 1: Load Python Libraries
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModelForSequenceClassification, TextClassificationPipeline, DataCollatorWithPadding, Trainer, TrainingArguments, BertForSequenceClassification, pipeline
from peft import PeftModel, PeftConfig, LoraConfig, TaskType, get_peft_model
import torch
import pandas as pd
import numpy as np
import osStep 2: Load medical diagnosis dataset
The textual description of symptoms in gretal/symptom_to_diagnosis dataset is labeled with 22 associated diagnoses, focusing on fine-grained single-domain diagnosis.
The data is split to 80% train (853 examples, 167kb) and 20% test (212 examples, 42kb).
data_files = {"train": "train.jsonl", "test": "test.jsonl"}
dataset = load_dataset("gretelai/symptom_to_diagnosis", data_files=data_files)
dataset = dataset.rename_column("output_text", "label")
print(dataset)Format the Dataset:
DatasetDict({
train: Dataset({
features: ['label', 'input_text'],
num_rows: 853
})
test: Dataset({
features: ['label', 'input_text'],
num_rows: 212
})
})Let’s check how our train data look like:
for entry in dataset['train'].select(range(5)):
print('INPUT: {} \nOUTPUT: {}\n'.format(entry['input_text'], entry['label']))Continue……… Check Back Tomorrow 🤗