Databricks released DBRX, an open, general-purpose LLM that outperforms other available open-source models on various benchmark tests. The model weights are available on hugging Face and GitHub for research as well as for commercial purposes.
DBRX Base and DBRX-Instruct
DBRX-Base and DBRX-Instruct are the latest open-source Mixture-of-Experts (MoE) models with 36B active and 132B Total Parameters. Both the base version (DBRX Base) and the fine-tuned version (DBRX Instruct) of DBRX are trained from stretch and can be executed or optimized on public, custom, or proprietary datasets.
| Feature | DBRX Base | DBRX Instruct |
|---|---|---|
| Model Type | Foundation Model | Pre-trained model for specific tasks |
| Customizability | Highly customizable for specific applications | Pre-programmed for following instructions and tasks |
| Purpose | Blank canvas for building specialized AI apps | Designed for tasks like question answering, summarization, creative writing, and coding assistance |
| Fine-Tuning | Requires fine-tuning for specific tasks | Pre-trained for few-turn interactions and task completion |
| Usage | Flexible across a range of applications | Specifically optimized for tasks within a conversation |
| Specialization | General-purpose, adaptable | Task-specific, optimized for instruction following |
A New State-of-the-Art Open LLM
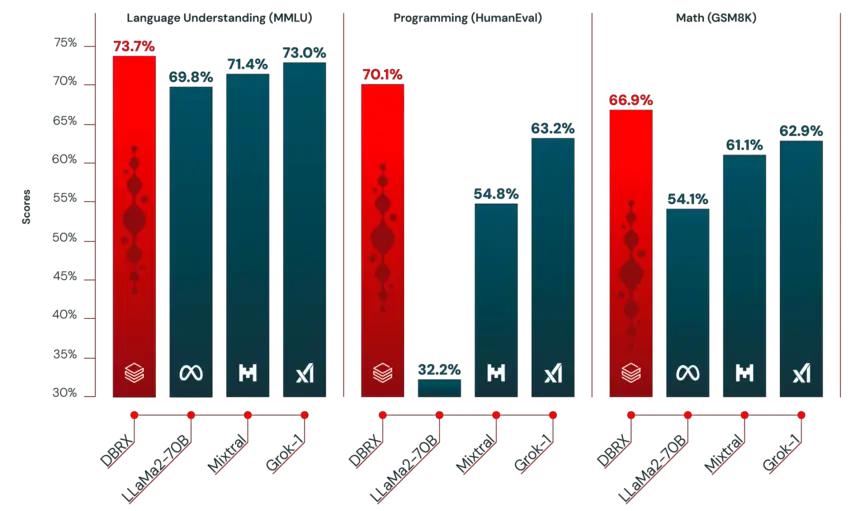
DBRX outperforms models such as LLaMA2-70B, Mixtral, and Grok-1 in language comprehension, programming, math, and logic tasks. The model has been identified by Databricks’ Gauntlet, an open-source benchmarking tool, to excel in over 30 advanced benchmarks, indicating ongoing enhancements to model quality.
In terms of efficiency and control, DBRX is the preferred choice for enterprises replacing proprietary models with open-source alternatives, as it outperforms GPT-3.5 in most tests. Databricks has observed this pattern among its 12,000+ client base, with many achieving higher quality and speed by customizing open-source models to their specific requirements.
Here are the key points about DBRX:
- Model Type: Utilizes a mixture-of-experts (MoE) architecture with 132B total, 36B active parameters.
- Model Base: It’s transformer-based decoder-only that was trained using next-token prediction.
- Training Data: Trained on 12 trillion tokens.
- Context Length: Supports a maximum context length of 32k tokens.
- Licensing: Follows a Llama-like license, with non-commercial terms allowing up to 700 million users and prohibiting training on outputs.
- Fine-Tuning: While details on fine-tuning are currently lacking, the Instruct model is pre-tuned for specific tasks, and it’s unclear whether reinforcement learning from human feedback (RLHF) was used.
- Estimated Cost: Estimated to cost $10-30 million, involving significant resources such as focused time, hardware, engineering efforts, and data contracts.
Comparison with other Models
| Model | MMLU | GSM8K | HumanEval |
|---|---|---|---|
| GPT-4 | 86.4 | 92 | 67 |
| Llama2-70B | 69.8 | 54.4 | 23.7 |
| Mixtral-8x7B-base | 70.6 | 74.4 | 40.2 |
| Qwen1.5-72B | 77.5 | 79.5 | 41.5 |
| DBRX-4x33B-instruct | 73.7 | 66.9 | 70.1 |
Quickstart Guide
Note: Manual approval is required to access the Base model.
Transformers library makes it simple to start working with DBRX models. The following packages and approximately 264GB of RAM are needed for this model:
! pip install transformers tiktokenThe hf_transfer package, as described by Huggingface, can be utilized to enhance download speed.
pip install hf_transfer
export HF_HUB_ENABLE_HF_TRANSFER=1To download the model, you will have to submit a request for access to this repository. After this is approved, provide the following token and receive an access token with read permission.
or
# Or requirements-gpu.txt to use flash attention on GPU(s)
pip install -r requirements.txt
# Add your Hugging Face token in order to access the model
huggingface-cli login
# See generate.py to change the prompt and other settings
python generate.pyThe requirements and generate.py file are available on GitHub repository here.
Run the model on a CPU:
Import necessary libraries:
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch- Load the tokenizer and model
- Replace “hf_YOUR_TOKEN” with your actual Hugging Face token
tokenizer = AutoTokenizer.from_pretrained("databricks/dbrx-instruct", trust_remote_code=True, token="hf_YOUR_TOKEN")
model = AutoModelForCausalLM.from_pretrained("databricks/dbrx-instruct",
device_map="cpu", # Use CPU for inference
torch_dtype=torch.bfloat16, # Use BFloat16 for efficient memory usage
trust_remote_code=True,
token="hf_YOUR_TOKEN")# Prepare the input text
input_text = "How to Fine-tune LLM?"
# Format the input as a chat message
messages = [{"role": "user", "content": input_text}]
# Apply the chat template and tokenize the input
input_ids = tokenizer.apply_chat_template(messages,
return_dict=True,
tokenize=True,
add_generation_prompt=True,
return_tensors="pt")
# To generate up to 200 new tokens
outputs = model.generate(**input_ids, max_new_tokens=200)
# Decode the generated text & Print
print(tokenizer.decode(outputs[0]))Run the model on multiple GPUs:
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("databricks/dbrx-instruct", trust_remote_code=True, token="hf_YOUR_TOKEN")
model = AutoModelForCausalLM.from_pretrained("databricks/dbrx-instruct", device_map="auto", torch_dtype=torch.bfloat16, trust_remote_code=True, token="hf_YOUR_TOKEN")
input_text = "What is Fine-tuning?"
messages = [{"role": "user", "content": input_text}]
input_ids = tokenizer.apply_chat_template(messages, return_dict=True, tokenize=True, add_generation_prompt=True, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids, max_new_tokens=200)
print(tokenizer.decode(outputs[0]))
If your GPU system supports FlashAttention2, you can add attn_implementation=”flash_attention_2” as a keyword to AutoModelForCausalLM.from_pretrained() to achieve faster inference.
Limitations and Ethical Considerations
Training Dataset Limitations
With a December 2023 knowledge cutoff, DBRX models were trained using 12T text tokens.
DBRX use a mixture of code and language examples in its training dataset. The most of the training text consists of English-language. However, DBRX’s proficiency in non-English languages has not been tested. Therefore, DBRX should be considered a generalist model for text-based tasks in English language. It does not have multimodal capabilities.
Associated Risks and Recommendations
Certainly, here are minor adjustments to your text:
All foundation models are cutting-edge technologies with a range of dangers and the potential to produce biased, offensive, incomplete, or erroneous information. Before utilizing or sharing such output, users should use caution and assess whether it is accurate and suitable for the use case they have in mind.
Retrieval augmented generation, or RAG, is advised by Databricks for situations where precision and authenticity are crucial. Additionally, i advise anyone utilizing or refining DBRX Base or DBRX Instruct to conduct extra safety testing within the parameters of their specific application and area.